

"What I cannot build, I do not understand"
~ Richard Feynman
There are over 27.7 million programmers in the world. How many of them do you think would know how to build a programming language? Very few. Why is it a good idea to build one in the first place? Understanding how programming languages work under the hood can empower you to be a more effective developer. You'll have a deeper appreciation for the tools you use daily. I had decided to give this crazy idea a try and it has been worth the effort I put in. I have decided to share what I have learned in this process, So it stays on the internet forever and I can read it whenever I want xD.
Prerequisites
Before diving into the development process, you should have a basic understanding of programming concepts and experience with at least one programming language. Familiarity with formal languages, compilers, and parsing is a plus but not strictly necessary. I always believe in learning by building. I learnt most of the concepts by building this project and so can you. I will list down all the reference materials I have followed to build this project at the very end.
Outline
There are two major types of programming language - Compiled and Interpreted. I chose to build an Interpreted language. Compiled languages are languages where the source code is compiled by the compiler and a binary file is generated. When you run this file, Your program is executed. When an Interpreted language is run, The interpreter executes line by line.

Here are the steps, which will be used as a basic map for this series:
Building a Lexer
Building a Parser
More on Parsing and Abstract Syntax Tree
Building an Interpreter
Deep dive into "Grammar" for the language.
In this article, Let's look into Lexer.
Lexer
Lexical Analysis/Scanning/Tokenizing is a method where the source code is broken down into something called tokens. This is used to recognize Keywords, Constants, etc. Tokens are the units which will be used to recognize these. So a Lexer is a peice of code which will take the source code, break it into tokens and return that.
Lets define some tokens below
TT_INT = 'INT'
TT_FLOAT = 'FLOAT'
TT_PLUS = 'PLUS'
TT_MINUS = 'MINUS'
TT_MUL = 'MUL'
TT_DIV = 'DIV'
Basic idea here is:
If I pass the string "1+2"
My lexer should return something like this:
[INT:1, PLUS, INT:2]
Let's look into the code and understand how a Lexer works. This is a very simple implementation of a lexer which scans arithmetic operations.
import re
#token types
TOKEN_INTEGER = 'INTEGER'
TOKEN_OPERATOR = 'OPERATOR'
# Regular expressions for token patterns,
# I have added integers and operators for now. Feel free to add more
patterns = [
(TOKEN_INTEGER, r'\d+'),# matches one or more consecutive digits
(TOKEN_OPERATOR, r'[+\-*/]'),
]
def tokenize(source_code):
tokens = []
while source_code:
matched = False
for token_type, pattern in patterns:
match = re.match(pattern, source_code)
if match:
value = match.group(0)
tokens.append((token_type, value))
source_code = source_code[len(value):]
matched = True
break
if not matched:
raise Exception(f"Invalid character in source code: {source_code[0]}")
return tokens
source_code = "1+2"
tokens = tokenize(source_code)
for token in tokens:
print(token)
Output:
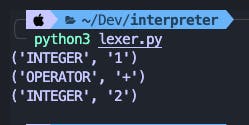
Play along with the code, Try for yourself.
The tokenize method essentially scans through the whole source code and matches each character with the token types using re library (Regular Expressions). It then returns the list of tokens. This is a very simple and naive implementation of a Lexer but it gets the work done for now.
Try it yourself
There are some problems with our code. Try to fix them yourself and test your understanding.
Our Lexer breaks when we include a whitespace in our source code. Try fixing it
+, -, *, / all are taken as Operators, You can tokenize each operator individually. This would be useful in the future.
References
One of the best series I have read online: https://ruslanspivak.com/lsbasi-part1/
This book is very good: https://craftinginterpreters.com
This series is gold: https://www.youtube.com/playlist?list=PLZQftyCk7_SdoVexSmwy_tBgs7P0b97yD
All of these resources helped me get started with Interpreters, Compilers and stuff. I highly recommend you all to check these resources.
Okay, that’s it for today. In the next article, I will probably introduce Parser, AST. Try implementing and fixing the problems our Lexer has for now.
Thank you for reading ◝(^ ^)◜